In this article, I will do my best to describe some of the data mining functionalities that are essential to any data mining process.
So before we get too deep into the specifics of the data mining functionalities. Let's begin by attempting to comprehend what exactly is meant by the term "data mining."
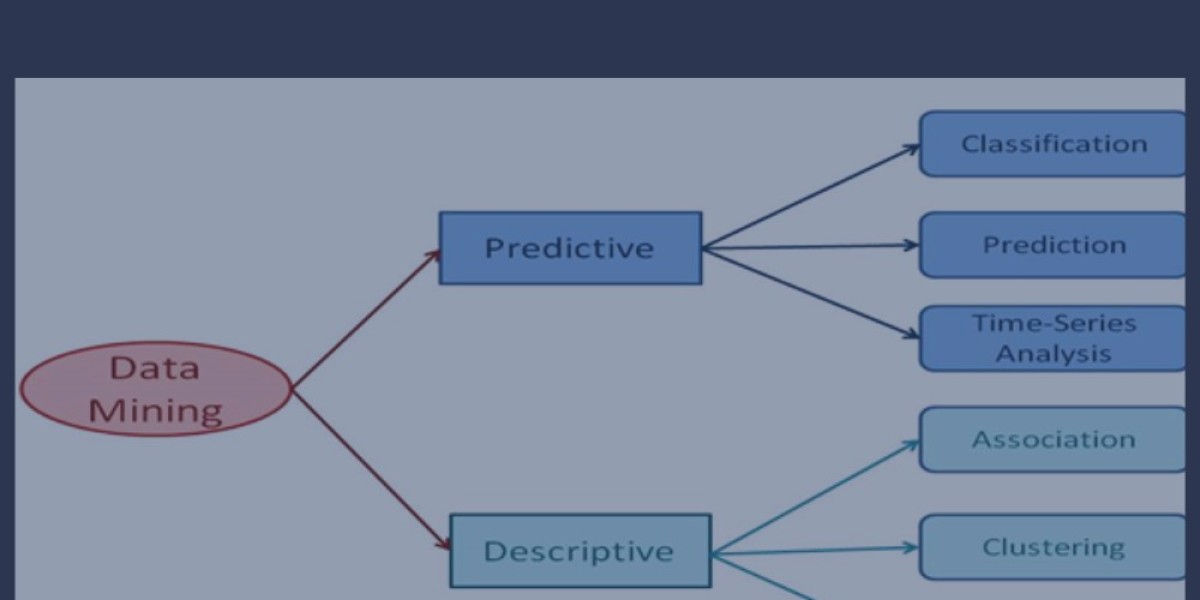
Meanwhile, data mining tasks can be classified as either:
The goal of descriptive data mining is to assist you gain an unbiased understanding of your data. The data set is structured around commonalities: statistics, totals, and similar measures.
Data prediction allows programmers to define properties without identifying them by name. Data mining can be used to forecast a company's key performance indicators (KPIs) by looking for a linear trend in the information. Using a patient's symptoms and the findings of a physical examination, a doctor can make a diagnosis and prognosis concerning the patient's health.
Symbolically, data mining's features represent elusive underlying patterns that must be unearthed. Both descriptive and predictive data analysis can benefit from data mining. Activities in descriptive mining characterize commonalities in the database's data, while tasks in predictive mining infer future outcomes based on the available information.
A wide variety of industries use data mining. You can use it to characterize your data and make predictions. However, Data Mining Features' principal purpose is to track innovations in data mining techniques. Several advantages become available when data mining is conducted in a methodical and scientific fashion.
Definitions, Types, and Categories
Defining a category or idea takes a specific set of information. One category includes the tangible goods found in a store, while another represents the abstract idea of how data can be organized.
One idea serves to classify, while the other highlights distinctions.
The term "data characterization" is used to describe the process of developing specific rules for identifying a target class from a general description of those attributes and qualities. This type of data collection is best exemplified by the statistical method known as attribute-oriented induction.
Discovering Commonalities
Finding patterns is the main purpose of data mining. We refer to these repetitions in the data as "frequent patterns." The collection covers quite a few different frequency bands.
Milk and sugar are examples of frequent item sets because they are often purchased together.
Common substructures that can be mixed with a set of objects or a series of things are trees and graphs.
Association Analysis
Examines the correlations present in a financial database. The term "market basket analysis" has another moniker in the retail industry because of its widespread use. The following criteria are used to determine the rules of association:
The data it offers shows which database entries are accessed the most often.
The Fourth Key Difference
In data mining, classification is the process of organizing data into categories based on your specifications. Using techniques such as if-then, decision trees, and neural networks, it makes predictions about a class or, more generally, a collection of elements.
Forecasting
You can use it to make educated guesses about things like future costs or volumes. Inferring an item's properties from its class attribute values or object attribute values is possible. The task may require the prediction of future numbers or the detection of changing patterns across time. Both numerical and class predictions are the mainstays of data mining.
We can develop reliable economic projections with the use of a linear regression model constructed from historical data.
Strategies for Clustering
Clustering is a common data mining technique used in numerous disciplines, such as image processing, pattern recognition, and bioinformatics. This is analogous to classifying, except the labels are up for grabs. Attributes of the data can be interpreted in terms of classes. Similar datasets are grouped together without being assigned a specific classification. Clustering algorithms organize information by dividing it into subsets with shared characteristics.
Analysis of Distinct Cases
Applying an outlier analysis helps clarify the reliability of the collected information. There are too many outliers to trust the data or look for patterns. The purpose of an outlier analysis is to see if out-of-the-ordinary data points signal a serious issue that requires fixing. The data presented by the algorithms cannot be used in an outlier analysis.
Conclusion
Data gathering gives useful information for making decisions. The way it works will get better over time. The patterns that data scientists will find during data mining are defined by the data mining functionalities. Data gathering is still limited. Finding patterns and links in big sets of data is called "data mining."